En mi empresa (Sngular) arrancamos el año con el lanzamiento de una nueva competencia: El Internet de las cosas (Internet of Things o IoT para los amigos). Pensamos que tenemos ya en la empresa todas las capacidades necesarias para combinar en hardware, software, cloud computing, data analytics, cognitive computing, machine learning… de forma que podamos ofrecer soluciones innovadoras en IoT y en especial al sector industrial, que ahora se enfrenta a la llamada cuarta revolución o Industria 4.0 y en el que ya hemos hecho una decena de proyectos muy interesantes.
Pero hoy no vengo a hablar de Sngular, quiero aprovechar para hablar un poquito de qué debemos entender o esperar de esto del IoT porque se tiende a banalizar lo que, a mi juicio, es el inicio de toda una nueva gran revolución en todos los sectores.
En la mayoría de los casos, cuando se piensa en ‘Internet’, se piensa automáticamente en ‘la web’, pero eso es como si cuando a uno le preguntases qué es la electricidad pensase únicamente en una bombilla que da luz y no viera que la bombilla es sólo uno de los muchos usos de la electricidad.
Como todos sabemos, con la electricidad, además de poder generar luz (con una bombilla o un led), también podemos generar calor (con una resistencia) o movimiento (con un motor eléctrico que puede mover un ventilador, un coche, una grúa o un ascensor).
De igual manera, Internet es la infraestructura, los protocolos y estándares que nos dan la capacidad de intercambiar información digital a nivel mundial. Encima de esta capacidad de comunicación, se desarrollaron multitud de servicios (para transferir ficheros, para mandar correos electrónicos, o para navegar por la web de contenidos que últimamente se han convertido en aplicaciones vistosas donde el formato ha triunfado sobre el contenido).
Por ello, dado que pensamos en web al hablar de Internet, nos hemos vuelto a inventar otra palabra, el «cloud» o la nube, para cuando Internet no tiene interfaz para los humanos, para cuando sólo nos queremos referir a la capacidad de almacenar todo en la red, proporcionando acceso universal desde cualquier dispositivo, y añadiendo además a la propia red ordenadores servidores para el procesamiento de dicha información de manera mucho más potente y eficiente que procesando la información con los ordenadores de las empresas o usuarios de la red.
Ya hemos hablado de lo que se nos viene a la cabeza por Internet pero, ¿qué pensamos sobre «las cosas»? Normalmente pensamos en los aparatos y máquinas más domésticos que tenemos a nuestro alcance y que manejamos directamente (el frigorífico, el coche, el móvil, la lavadora, o las luces y persianas de nuestra casa).
Por eso, cuando se habla de Internet de las cosas, la noticia del telediario solía ser hasta hace poco la de una pantalla táctil para navegar por Internet desde la puerta del frigorífico (que coincidiréis conmigo en que es el lugar en el que más cómodamente uno puede consultar las redes sociales o las recetas de cocina o hacer la compra de los huevos que vemos que faltan en el frigorífico). También nos imaginamos un Internet de las cosas que se limite a ampliar las funciones de nuestra pantalla del coche para reproducir mis canciones favoritas desde Spotify. Y no digamos la maravilla que supone que con el móvil podamos decirle de camino a casa que el horno se encienda para que el pollo esté a punto cuando lleguemos al hogar. Se da por hecho que la preparación previa del pollo es lo de menos.

Sin duda, esa capacidad de conectar nuestras cosas, nuestros cacharros, para que sea más fácil manipularlos, parece revolucionaria y cómoda, pero os aseguro que ese no es el IoT que lo va a revolucionar todo; tendemos a simplificar, pensando que esto de las cosas inteligentes sólo se aplica a lo que nosotros usamos, cuando la mayoría de las cosas que se van a ir haciendo inteligentes van a empezar a «hablar» entre ellas, sin que nosotros nos enteremos ni intervengamos de ninguna manera: un semáforo con un coche, un coche con otro coche, un candado o una alarma con una cámara que reconozca una cara, un sensor de humedad y un GPS con un tractor que se conduzca sólo, un contenedor de basura con un camión de basura…
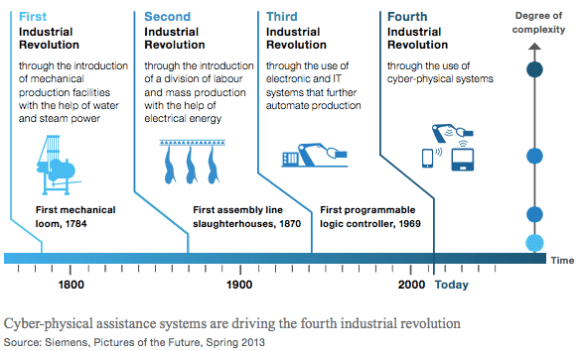
Es ese «Internet silencioso», el que no tiene interfaz gráfico para los humanos, el cloud que se limita a conectar todo, a almacenar la información de todo… y la conexión al cloud de trillones de dispositivos, sensores, máquinas, microprocesadores o pequeñas inteligencias repartidas por todas las máquinas cada vez más autónomas, máquinas que no son ya manejados por personas, máquinas que hablan con máquinas (M2M o Machine to Machine); ese Internet, decíamos, es realmente el que va a revolucionar la industria en la llamada cuarta revolución industrial o Industria 4.0.
Para simplificar, la primera revolución industrial fue la facilitada por la máquina de vapor, la segunda por la electricidad, la tercera por la electrónica e informática, y la cuarta es la que facilita internet por la que se mezclan máquinas físicas y lógicas, las máquinas hablan con las máquinas (M2M), y empezamos a hablar de cyberObjetos (objetos inteligentes y conectados), o de Internet for Everything o Internet de las Cosas (IoT) que son únicamente nombres marketinianos de los que nos vamos aburriendo sucesivamente.
Os pongo algunos ejemplos sencillos que ya son posibles con la tecnología actual y que irán inundando nuestras vidas, nuestros objetos, nuestros edificios, nuestras fábricas, nuestros hospitales, nuestras escuelas, nuestras ciudades de manera progresiva e imparable.
El cerebro de un ascensor

El cerebro del ascensor sabrá en qué estado de desgaste están todas las piezas del sistema, según su uso; enviará informes detallados a su central; anticipará fallos en sus sistemas solicitando sustitución de piezas o revisiones técnicas específicas mientras sube y baja por los pisos de un rascacielos a petición de las personas que pulsan los botones, abriendo y cerrando sus puertas automáticamente; aprenderá a ser más eficiente para usar la energía, para tardar menos tiempo, pero también hablará con el resto de ascensores del edificio, y con las escaleras mecánicas, y se «entretendrán» en observar cuánta gente entra, o sale, en cada planta, en cada momento, y observarán a sus pasajeros y calcularán con mucha precisión de qué peso, de qué altura, de qué género, de qué edad, de qué costumbres son; podrán saber y podrán predecir cuánta gente hay o habrá en cada planta en cada horario, según el día de la semana, cómo se ven afectados estos patrones si se toman decisiones en el edificio. Si este edificio es un centro comercial, podrá servir para optimizar las ventas. Si este edificio es de oficinas, probablemente también tendrá contadores de personas en salas de reuniones, optimizará cómo se gasta energía en climatizar, en limpiar las oficinas, en aprovechar mejor las instalaciones según la cantidad de personas que lo utilizan en cada momento. Lo lógico es que estos edificios nos empiecen a hacer recomendaciones y nos propongan escenarios que podamos simular y que permitan optimizar los horarios, o la distribución de la actividad, o mejorar los costes de mantenimiento o la eficiencia energética.
Nuestro coche.

Nuestro coche, con un corazón cada vez más electrónico, no sólo nos mostrará la pantalla multimedia de última generación, monitorizará el estado de todos sus componentes, anticipará averías, guiará al técnico en la reparación o revisión y seguirá siendo cada vez más eficiente y barato de mantener, sino que también tendrá información, muy codiciada por nuestro seguro o por muchas empresas, acerca de cómo usamos el coche, qué estilo de conducción tenemos, por dónde nos movemos, cuál es la ruta idónea, qué está haciendo el coche de 5 coches delante nuestro en un atasco o, al cruzarnos con otros coches, se intercambiarán con detalle el estado del firme que nos vamos a encontrar en los próximos kilómetros y que acaban de ser escaneados por el coche que venía en sentido contrario. En muy poco tiempo, el coche podrá llevarnos a cualquier sitio de manera autónoma porque, sin duda, será mucho más seguro que conduzca la máquina, que tendrá mucha más información, muchos más reflejos y mucho más control de la conducción. Los semáforos luminosos para humanos serán completamente prescindibles. Se evitarán mucho mejor los atascos. Desaparecerá el problema de «aparcar».
Los coches llevarán a nuestros hijos al colegio y luego se volverán a casa a esperarnos o nos irán a recoger al trabajo pasando previamente para que les carguen la compra. La ciudad cambiará dinámicamente sus reglas para que la circulación sea ágil, para que los parkings se utilicen de manera eficiente, para que la contaminación disminuya, aprenderá de lo que le digan los coches y los coches se adaptarán a lo que les digan los elementos de la ciudad. Cuando lleguemos con nuestro coche eléctrico, conectado, a la plaza de aparcamiento de la oficina, el coche negociará con el enchufe y decidirá si le interesa comprar electricidad o venderla a la ciudad si no la vamos a necesitar antes de volver a casa y producimos en casa más barato que el precio al que se compra en el barrio industrial, y en ese mismo momento se producirá la microtransacción económica que corresponda que, aunque sea de unos pocos céntimos, se hará de manera automática, porque las transacciones económicas tendrán un coste de transacción marginal y despreciable. Al dejar el coche en casa por la noche, el coche nos preguntará si nos parece buena idea que se vaya el solo a las 4 de la mañana a pasar la ITV del futuro porque ha visto en nuestra agenda que no queremos hacer nada a esa hora y que es la mejor hora para gastar menos energía en ir a la ITV.
Industria 4.0
En nuestra fábrica 4.0 todas las magnitudes, de cada pieza, de cada máquina, de cada consumible, estarán monitorizadas en tiempo real. Se guardarán todos los datos para ver las curvas de evolución de desgaste, para hacer un análisis predictivo de cuándo hay que hacer un cambio de aceite, cuándo hay que cambiar una pieza, cuándo hay que parar un máquina para mejorar el consumo eléctrico, aumentar la producción, reducir los escasos stocks necesarios de consumibles (porque tendremos la capacidad de predecir su consumo) o los escasos stocks de productos generados (porque fabricaremos bajo demanda en tiempo real e incluso prediciendo la demanda).
Salud

En nuestra salud, la revolución ya la vamos intuyendo… las cosas a «iotizar» son sensores y actuadores cada vez más diminutos capaces de monitorizar y compensar todo tipo de constantes vitales, concentración de sustancias en sangre o en el sudor, o en el estómago o de predecir cuándo se desequilibran los sistemas de nuestro cuerpo. Recordemos que la salud no consiste en otra cosa sino en el mantener el equilibrio de muchas variables en sus rangos adecuados, en los que la vida se desarrolla y en los que nuestros órganos están diseñados para autocompensarse; y que las máquinas y sistemas autónomos perseguirán contínuamente el restablecimiento de los equilibrios de todas esas variables ante variaciones producidas por enfermedades o accidentes. De esta forma, al igual que hoy el piloto automático de un avión compensa un sistema de guiado dinámico midiendo y controlando multitud de variables mientras va acercando el avión a la pista de aterrizaje, tendremos sistemas de monitorización vital que, en piloto automático, persigan restablecer los equilibrios para, de esa forma, proteger, alargar y mejorar nuestra vida.
No quiero extenderme con ejemplos en todos los sectores, de la gran industria, de las infraestructuras de producción y distribución de energía, de la agricultura, la logística, el comercio de distribución… No se trata de ser exhaustivos en imaginar todo lo que va a cambiar en cada sector porque simplemente el IoT lo va a cambiar absolutamente todo en una o dos décadas.
Tampoco quiero incluir aquí todas esas fotos e infografías futuristas e impactantes sobre de las cosas conectadas en la fábrica o en el hogar, porque simplemente cualquier ejemplo nos limita nuestra imaginación para pensar y redefinir lo que nos espera.
Al que le parezca que todas estas cosas nunca llegan, sólo tiene que mirar hacia atrás: sin duda nos fiaremos completamente de un coche que se conduzca solo al igual que hoy no entendemos que para subir al décimo piso tengamos que necesitar un ascensorista de uniforme para manejar el ascensor, nos dejaremos operar por una máquina programada para nuestra apendicitis, igual que hoy preferimos que las dioptrías del ojo las corrija automáticamente un láser y no un cirujano con muy buen pulso.
Estamos al principio de una gran revolución, de los objetos fabricados de manera personalizada, en el momento y lugar que sean necesarios, de objetos inteligentes que cuenten con toda la información del entorno necesaria para autorepararse, para adaptarse aprendiendo y mejorando de manera automática en función del uso que les demos.
Todos los objetos físicos podrán estar conectados con el resto de objetos del mundo y con centros de procesamiento inteligente que tendrán acceso a toda la información necesaria y de esta forma todos los objetos podrán ser extendidos con una identidad digital que los complemente y mejore.
La conexión a Internet, a esa gran red donde encontrar toda la información y toda la capacidad de proceso que sea necesaria, hará que cualquier pequeño objeto, ya sea un sensor de humedad, una cerradura o un candado de bicicleta, una mochila, una señal de tráfico, un oso de peluche, un llavero, un bolígrafo… empiecen a parecer cada vez más inteligentes gracias a la versión digital que acompañará a todo objeto.
Utilizaremos la voz, o nuestro móvil, para preguntar a una mesa sobre sus características, sobre su fabricante, sobre su coste y el objeto (vía aplicación móvil o como sea, nos responderá con atributos, características…). En una tienda de muebles, le preguntaremos a un sofá (ya veremos si le preguntamos desde el móvil o desde las lentillas que sobreimpresionen información sobre lo que vemos) que si nos cabe en el rincón de nuestro salón o a un coche que nos guste y que esté aparcado en la calle que cuánto nos costaría su compra y mantenimiento anual para nuestro estilo de vida y conducción. Podremos comprar cualquier objeto que veamos, la ropa que llevan puesta los demás, un cuadro que nos guste de la recepción de un hotel, cualquier imagen de una revista o anuncio de televisión…gracias al reconocimiento de imagen y la conexión con el comercio electrónico del futuro. Nuestros hijos verán muy poco útiles esos objetos físicos que no tengan esa conexión o identidad digital que los complemente: será parecido a la sensación que hoy tienen nuestros pequeños cuando cogen una revista e intentan hacer zoom sobre una foto utilizando los dos dedos como hacen con cualquier imagen que ven en una tableta.
Hoy ya la impresora de casa se compra por internet sus propios cartuchos de tinta cuando se empieza a agotar si así lo hemos autorizado previamente. Pronto tendremos que revisar el presupuesto que damos a cada objeto para su automantenimiento pero también los objetos tomarán decisiones según el contexto para hacernos ahorrar o incluso hacernos ganar dinero (por ejemplo, si la regulación finalmente nos deja producir electricidad a partir del sol que cae en nuestro tejado, nos permite transportarla en la batería de nuestro coche, y venderla a la ciudad aprovechando el estacionamiento del coche mientras damos un paseo de compras por el centro).
Sólo espero que toda esa liberación de tareas y ese tiempo libre que tengamos gracias a los miles de objetos que nos rodeen dispuestos a ayudarnos o hacernos la vida más fácil nos deje algunos placeres sencillos e insustituibles que no requieran ser automatizados: espero que no mandemos un par de drones para que salgan de paseo con nuestros hijos y con nuestro perro con la misión de cuidar de la seguridad de los primeros y de lanzar el palo o recoger las cositas del segundo (alguien estará ya también pensando en esta aplicación del Internet de las cosas… marrones).
Es previsible también que aparezcan aplicaciones absurdas y noveleras para algunos pero que parezcan vitales y transformadoras para otros (como ese pañal que cuando siente la humedad envía un ‘wasap’ al padre o la madre, que supongo que podrá saltar del sofá de un brinco para cambiar el pañal al niño antes incluso de que el niño se encuentre incómodo y empiece a llorar, sin duda una disrupción para el hogar).
Lo que está claro es que todo está por hacer, por reinventar; que estamos ante una nueva era en la que podemos hacernos la vida más cómoda, más eficiente y económica, más saludable, más respetuosa con todos los demás y con el medio ambiente.
El momento que vivimos es especialmente emocionante porque dependemos cada vez menos de la disponibilidad de la tecnología necesaria, que ya está aquí, y más de la imaginación y del conocimiento profundo del ser humano que nos permita entender las necesidades que realmente queremos satisfacer.










![[Reproduce]](https://a248.e.akamai.net/f/1731/67675/12h/si.wsj.net/public/resources/images/P1-BD630_Reprod_E_20111201191059.jpg)
